Data Transfer Between Databases
- DarkLight
Data Transfer Between Databases
- DarkLight
Article Summary
Share feedback
Thanks for sharing your feedback!
Overview
It may be useful to move tables from one database or cluster to another, a common issue when it comes to backing up work or sharing it with other users. AWS offers no direct way of accomplishing this but, fortunately, we can create some fairly simple jobs within Matillion ETL that will do the work.
The general strategy is to Unload table data from a Redshift cluster to a file on an S3 Bucket, then Load the data from that file back into a different table in another database. Thus, the data is copied from one database to another, even if the two databases exist on different clusters or regions.
Viewing this task through Matillion ETL means moving a table from one environment to another, where an environment describes a connection to Redshift. If you are moving an environment from one schema to another within the same environment, the component Schema Copy can be used instead and is much simpler.
Unloading data to an S3 Bucket.
Note: We must have an environment set up for Redshift connection that houses the table to be copied and this environment must be currently active/selected. In this example, we are moving a data from a Test database to a Live database, each with their own environment.
The first step is to create a file on an S3 Bucket from the table we want to copy. This can be accomplished by an S3 Unload Component linked to a Start component. The S3 Unload Component is set up to take an existing table from this Environment's default schema (although any schema can be used) and place it into the specific S3 Bucket. The name of the file inside the S3 Bucket is given by the 'S3 Object Prefix' property.
To finish this step, the created job should be run.
Uploading to a different Redshift database.
Now switch environments so the active/selected environment is the one we wish to transfer the data to. This can be done by right-clicking the other environment and clicking 'Select Environment'.
Another Orchestration job is created and filled with three components: Start, Create/Replace Table and S3 Load.
Create/Replace table is simply used to create a blank table in the Redshift database with a name that must then also be used by S3 Load to load data into. In this case, we make another table called example_table so that our new table will, by the end of the process, be exactly identical to the original. S3 Load is set up to load all columns of data from the file we wrote to the S3 Bucket. The bucket is linked to in the 'S3 URL Location' property and the file itself in the 'S3 Object Prefix' property.
Note that the file must be loaded in the same way it was unloaded in regards to being delimited. If S3 Unload in the previous job was told to delimit using tabs, S3 Load must be given the same properties.
It may be convenient to use the S3 Load Generator (Redshift) instead of manually creating the Create/Write Table and S3 Load Components.
Using a Manifest file
The S3 Load utility can optionally be made to use a manifest file, with the additional benefit of ensuring that none of the files are missing when it performs the load.
When an S3 Unload is run with the "Parallel" property set to yes, multiple output files are generated. Without a manifest, if one of the output files is missing the S3 Load will still complete successfully, but only actually loading a subset of the data.
Matillion’s S3 Manifest Builder component is a great way to build a manifest file, and is best added to an orchestration immediately after an S3 Unload.
Job synchronization using SQS
If you’re running separate instances of Matillion on the two clusters, it’s quite straight forward to take advantage of Amazon’s SQS queueing service to synchronize the import and export components.
- The "source" instance sends an SQS message when the unload has successfully finished
- The "target" instance is listening to the same queue, and launches the COPY command when it receives the SQS message.
To have Matillion ETL listen to an SQS queue, follow the instructions here. You would configure this on the target instance.
To have Matillion ETL push a message onto an SQS queue, use the SQS Message component, which is fully documented here. In this case, the message needs to be a piece of JSON text in the format that the target instance will understand, and so needs to name them group, job, environment and version of the S3 import job.
To have Matillion ETL push a message onto an SQS queue, use the SQS Message component, which is fully documented here. In this case, the message needs to be a piece of JSON text in the format that the target instance will understand, and so needs to name them group, job, environment and version of the S3 import job.
Example
You will need two separate environments in order to run this example. Either one instance with two environments, or two instances: one for the source cluster and one on the target cluster.
The target instance must have its SQS listener switched on, as described here, listening to the SQS queue named in the below CX Data Export job.
There are three Matillion jobs in the attached export:
- CX Data Export - the export job, which runs on the source cluster.
- CX Prep data for export - Called by CX Data Export to prepare sample data for export.
- CX Data Import - the import job, which runs on the target cluster.
CX Data Export
The components look like this:
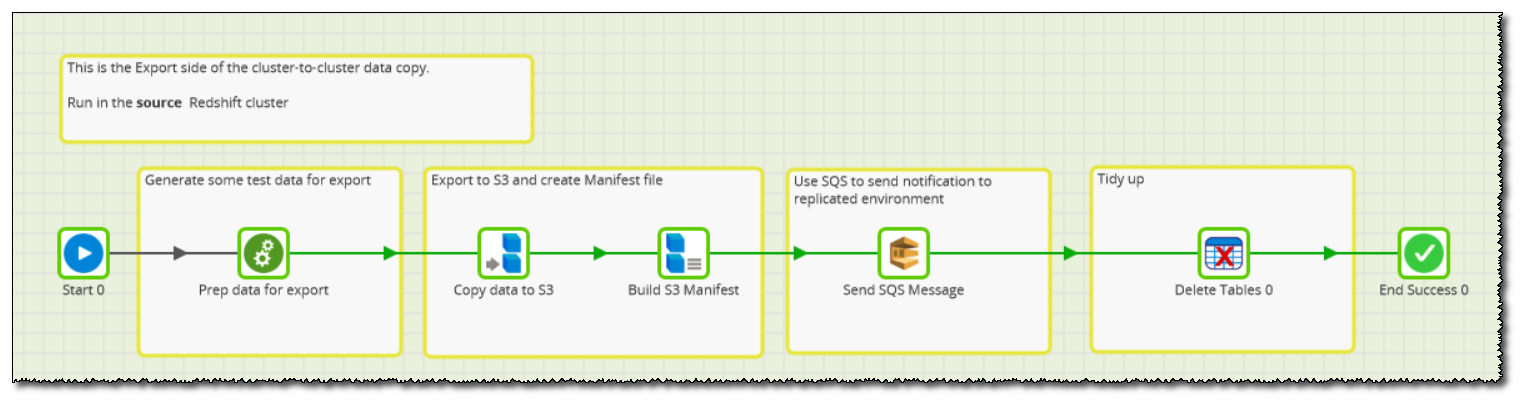
First to execute is a call to "CX Prep data for export", which creates a new Redshift table named tmp_10240000, containing sample data to demonstrate the export.
Next, an S3 Unload component creates files in a nominated S3 staging bucket (named via an Environment Variable). Parallel is set to Yes so multiple files will be created with a common prefix.
After the unload has finished, an S3 Manifest Builder component generates a named Manifest file in the same location. This will be used by the importer to verify that all the files have been included.
In order to notify the target cluster that new data is available, an SQS Message component is used to send a JSON message onto a named queue. This will be picked up by a Matillion instance running on the target cluster.
Finally, the Delete Tables component removes the tmp_10240000 table from the source cluster.
First to execute is a call to "CX Prep data for export", which creates a new Redshift table named tmp_10240000, containing sample data to demonstrate the export.
Next, an S3 Unload component creates files in a nominated S3 staging bucket (named via an Environment Variable). Parallel is set to Yes so multiple files will be created with a common prefix.
After the unload has finished, an S3 Manifest Builder component generates a named Manifest file in the same location. This will be used by the importer to verify that all the files have been included.
In order to notify the target cluster that new data is available, an SQS Message component is used to send a JSON message onto a named queue. This will be picked up by a Matillion instance running on the target cluster.
Finally, the Delete Tables component removes the tmp_10240000 table from the source cluster.
CX Data Import
The components look like this:
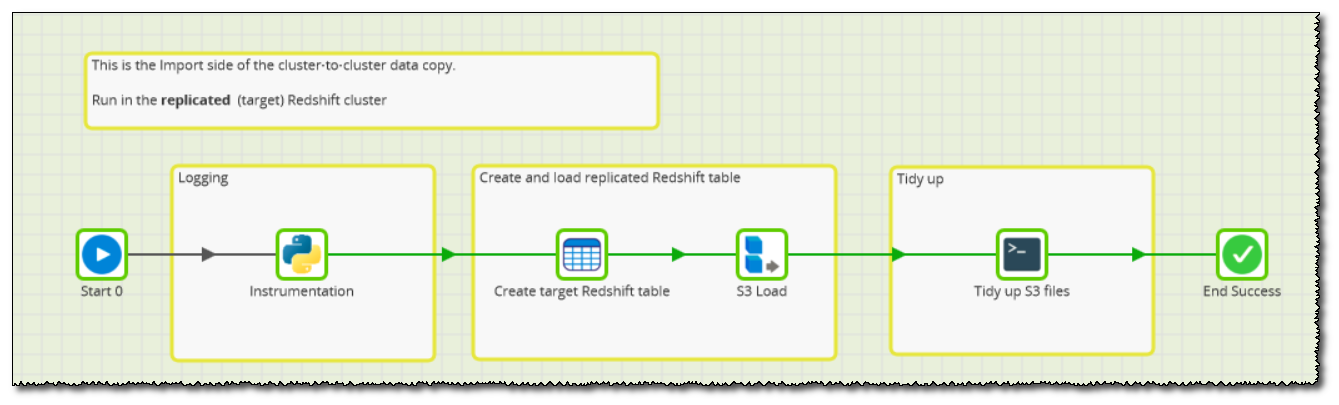
First of all, the Python script just does some basic logging of the parameters which are going to be used.
Then, a Create/Replace Table component creates a table named replicated_table, ready to receive a copy of the source data.
A parameterised S3 Load then copies the source data from S3 into the target Redshift cluster using the named Manifest file. This component will fail if not all the files are present.
Finally the tidy up is performed by a Bash script, which deletes all the data files including the manifest itself
First of all, the Python script just does some basic logging of the parameters which are going to be used.
Then, a Create/Replace Table component creates a table named replicated_table, ready to receive a copy of the source data.
A parameterised S3 Load then copies the source data from S3 into the target Redshift cluster using the named Manifest file. This component will fail if not all the files are present.
Finally the tidy up is performed by a Bash script, which deletes all the data files including the manifest itself
Users can find a job attached below that adheres to these examples and can be imported to provide a base for data transfer solutions.